あるサイトに含まれるリンク一覧を取得したいという要望があった。最初PHPでやろうとしたのだが、スクレイピングでググるとPythonの記事ばかり出てきてPython書けって言われてる気がしたのでPythonで書くことにした。
Pythonをインストール
以下Windows10環境
https://www.python.org/
のトップからポチッとダウンロードすればいいと思いきや、ここからだとどうも32bit版っぽい上に環境変数がうまく通らなかった。ので
https://www.python.org/downloads/release/python-365/
からWindows x86-64 executable installerをダウンロードしてインストールすればよさげ。インストールする際は環境変数を通すオプションに忘れずにチェックしておこう。
インストールできたら通例通り
|
1 |
python –-version |
とか打ってインストールできているか確認しておく
ライブラリの選定
で、スクレイピングってどうやるんだ?って考えると要するにcurl的なコマンドでgetしてある条件に合致したものを出力すればよい。条件は頑張って正規表現書けばいいのだろうが、どう考えても非効率的なのでスクレイピングに適したライブラリを探して使うべきだ。
「Python スクレイピング」とかって調べるとすぐにBeautifulSoupを使えって言われる。
BeautifulSoup
なるほど、多機能そうだしPythonでスクレイピングするならこれ!といった感じはする。が、複雑なことするわけじゃないしもっと簡単なライブラリはないかと思って調べたところpyqueryに行き着いた。
pyquery
名前からお察しの通りjQueryライクな書き方ができるので、Web系の人間にはとっつきやすそう。
|
1 |
pip install pyquery |
でインストールする。
下準備はこれでOK。コードを書いていこう。
とりあえずprintしてみる
適当にscraping.pyなどというファイルを作成し、コードを書いていこう。
とりあえずpyqueryを読み込む
|
1 |
from pyquery import PyQuery as pq |
で、取得したいURLを指定してpyqueryで拾ってくる。
|
1 2 3 4 |
#URLを指定 url = 'https://spc-jpn.co.jp' #htmlを取得 html = pq(url = url) |
今回はサンプルとして弊社コーポレートサイトのフッターにあるリンクを全て取得する。フッターに全ページへのリンクが貼られている場合が多いので、応用すればサイトマップを作成するなどにも役立つだろう。
「フッターのリンク」を指定するためにDOM構造を解読する。デベロッパーツールを用いて眺めてみると”nav.l-footer-navi”の中のリンクを取れば良さそうだということが分かる。今回は単純なDOM構造なので使う必要はないが、より詳細な指定をしたい場合はデベロッパーツールのセレクタをコピーする機能を用いるといいだろう。
|
1 |
body > footer > div.wrap > nav > ul > li:nth-child(1) > dl > dd:nth-child(2) > a |
こんな感じの詳細なセレクタを取得できる。
要素を取得したら、for文で回してリンクテキストとリンク先を出力してみる。
|
1 2 3 4 5 6 7 |
#要素を指定 links = html.find('.l-footer-navi a') #取得した要素を回して出力 for link in links: val = pq(link) print(val.text()) print(val.attr('href')) |
これだけ、超簡単。実行してみよう。
|
1 |
python scraping.py |
って打って
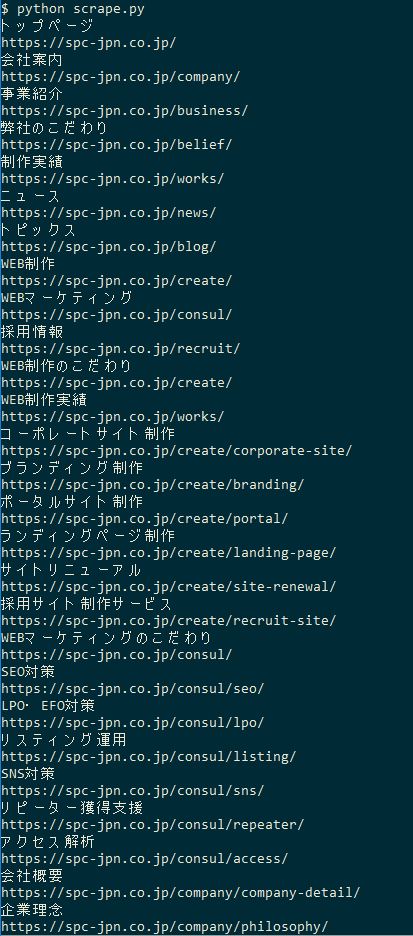
のように一覧が出力されれば成功。
なのだが、このままだと黒い画面上で結果が見れるだけなのでイマイチ使い道がない。これらをcsvなりjsonに吐き出しておけばあとでなにかしたい時便利そう。
今回はjsonに出力してみる。
jsonに書き込む
先立ってゴールを示すと
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 |
{ "0": { "URL": "https://spc-jpn.co.jp/", "Title": "トップページ" }, "1": { "URL": "https://spc-jpn.co.jp/company/", "Title": "会社案内" }, "2": { "URL": "https://spc-jpn.co.jp/business/", "Title": "事業紹介" }, "3": { "URL": "https://spc-jpn.co.jp/belief/", "Title": "弊社のこだわり" }, "4": { "URL": "https://spc-jpn.co.jp/works/", "Title": "制作実績" }, "5": { "URL": "https://spc-jpn.co.jp/news/", "Title": "ニュース" }, "6": { "URL": "https://spc-jpn.co.jp/blog/", "Title": "トピックス" }, "7": { "URL": "https://spc-jpn.co.jp/create/", "Title": "WEB制作" }, "8": { "URL": "https://spc-jpn.co.jp/consul/", "Title": "WEBマーケティング" }, "9": { "URL": "https://spc-jpn.co.jp/recruit/", "Title": "採用情報" }, "10": { "URL": "https://spc-jpn.co.jp/create/", "Title": "WEB制作のこだわり" }, "11": { "URL": "https://spc-jpn.co.jp/works/", "Title": "WEB制作実績" }, "12": { "URL": "https://spc-jpn.co.jp/create/corporate-site/", "Title": "コーポレートサイト制作" }, "13": { "URL": "https://spc-jpn.co.jp/create/branding/", "Title": "ブランディング制作" }, "14": { "URL": "https://spc-jpn.co.jp/create/portal/", "Title": "ポータルサイト制作" }, "15": { "URL": "https://spc-jpn.co.jp/create/landing-page/", "Title": "ランディングページ制作" }, "16": { "URL": "https://spc-jpn.co.jp/create/site-renewal/", "Title": "サイトリニューアル" }, "17": { "URL": "https://spc-jpn.co.jp/create/recruit-site/", "Title": "採用サイト制作サービス" }, "18": { "URL": "https://spc-jpn.co.jp/consul/", "Title": "WEBマーケティングのこだわり" }, "19": { "URL": "https://spc-jpn.co.jp/consul/seo/", "Title": "SEO対策" }, "20": { "URL": "https://spc-jpn.co.jp/consul/lpo/", "Title": "LPO・EFO対策" }, "21": { "URL": "https://spc-jpn.co.jp/consul/listing/", "Title": "リスティング運用" }, "22": { "URL": "https://spc-jpn.co.jp/consul/sns/", "Title": "SNS対策" }, "23": { "URL": "https://spc-jpn.co.jp/consul/repeater/", "Title": "リピーター獲得支援" }, "24": { "URL": "https://spc-jpn.co.jp/consul/access/", "Title": "アクセス解析" }, "25": { "URL": "https://spc-jpn.co.jp/company/company-detail/", "Title": "会社概要" }, "26": { "URL": "https://spc-jpn.co.jp/company/philosophy/", "Title": "企業理念" }, "27": { "URL": "https://spc-jpn.co.jp/company/history/", "Title": "会社沿革" }, "28": { "URL": "https://spc-jpn.co.jp/company/office/", "Title": "事業所紹介" }, "29": { "URL": "https://spc-jpn.co.jp/company/group/", "Title": "グループ紹介" }, "30": { "URL": "https://spc-jpn.co.jp/company/staffs/", "Title": "メンバー紹介" }, "31": { "URL": "https://spc-jpn.co.jp/question/", "Title": "よくある質問" }, "32": { "URL": "https://spc-jpn.co.jp/contact/", "Title": "お問い合わせ" }, "33": { "URL": "https://spc-jpn.co.jp/policy/", "Title": "プライバシーポリシー" }, "34": { "URL": "https://spc-jpn.co.jp/security/", "Title": "情報セキュリティ基本方針" } } |
こんな感じのものを吐き出したい。
htmlを取得してその中の任意の要素を取り出すところまではさっきと同じ。
PythonではPHPでいうところの連想配列のことを辞書(ディクショナリ)と呼ぶ。つまり、先程取得できたタイトルとURLを辞書に突っ込んでjsonに書き込めばいいのだろうというアタリはすぐにつく。
で、連番振りたいんだけどどうすりゃいいの?ってところで出てくるのがenumerate関数。これを使えばインデックス番号(連番)と要素をスマートに出力できる。
|
1 2 3 4 5 |
arr = {}#辞書を初期化 for i, link in enumerate(links): val = pq(link) arr[i] = {'URL': val.attr('href'), 'Title': val.text()} print(arr) |
こんな感じ。’i’にインデックスが入り、’link’に要素が入る。printしてjsonっぽいものが吐き出されていることを確認しよう。
あとはjsonに書き込むだけなのだが、やっぱり日本語の文字化け問題が起こった。文字化けを回避するにはcodecsライブラリを用ればよさそう。jsonライブラリと併せてインポートしておこう。
|
1 |
import json, codecs |
そして適当なファイルに書き込む。
|
1 2 |
with codecs.open('links.json', 'w', 'utf-8') as json_file: json.dump(arr, json_file, ensure_ascii=False, indent=4) |
忘れちゃいけないのがensure_ascii=Falseオプション。これを忘れるとありがたいことに日本語がエスケープされてしまう。また、indentオプションをつけることで可読性が保てる。人間が読む必要なくて機械的に処理するだけなら不要かも知れない。
まとめるとできあがったコードは
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# coding: UTF-8 from pyquery import PyQuery as pq import json, codecs # アクセスするURL url = 'https://spc-jpn.co.jp' #htmlを取得 html = pq(url = url) #要素を指定 links = html.find('.l-footer-navi a') #取得した要素を回して辞書に格納 arr = {}#辞書を初期化 for i, link in enumerate(links): val = pq(link) arr[i] = {'URL': val.attr('href'), 'Title': val.text()} #適当なjsonファイルに書き込む with codecs.open('links.json', 'w', 'utf-8') as json_file: json.dump(arr, json_file, ensure_ascii=False, indent=4) |
こんな感じで先に示したjsonを無事出力できた。
注意事項
Webスクレイピングはサーバーに負荷がかかるので、よそ様から何かを引っ張ってくる際は迷惑にならないようにマナーを守ろう。そもそもあまりに負荷をかけると弾かれてしまう場合もある。
Webスクレイピングの注意事項一覧
法的な話は逐一チェックするとして、コーディングする側の人間はできるだけサーバーへのアクセスが減るよう設計しよう。
また、連続してアクセスする際は数秒の間隔が空くようにsleepを挟むようにしないとダメ。筆者はこれを忘れて怒られた。
一言
Webスクレイピングは覚えておくと色々できそうな気がしていたので着手するきっかけがあってよかった。どんなデータをどのように扱うかアイデア次第でいくらでも活用できる。
あとPython書こう書こうと思ってなかなか機会がなかったのでいいきっかけとなった。インデントを遵守しないと動かない系の言語に抵抗があったのだが、書いてみると実に綺麗。もうちょっと踏み込んで学習したいところだ。